AI & Law
Avoiding AI Vendor Lock-In: Multi-Model Architecture, Contract Clauses & Exit Strategy (2026 Guide)
Your AI vendor raises prices overnight, shuts down the model your workflow runs on, or disappears from the market entirely — and your processes grind to a halt. AI vendor lock-in is no longer a theoretical risk in 2026; it’s an operational reality. The good news: you can protect yourself technically and legally. This guide shows you how — from someone who builds the architecture and negotiates the contracts.
What is AI vendor lock-in?
AI vendor lock-in refers to dependence on a single AI provider that makes switching technically, contractually, or data-wise expensive or impossible. It arises when business logic is hard-wired to a proprietary interface, when contracts impose high exit barriers, or when your data, embeddings, and fine-tunes reside exclusively with the provider.
The dependence therefore has three faces:
- Technical: Your code talks directly to one provider’s proprietary API. Switching means rebuilding.
- Contractual: Long terms, termination hurdles, exit fees, or the absence of export obligations keep you locked in.
- Data-related: Your prompts, vector embeddings, and painstakingly created fine-tuning data sit in a format and a location that only this provider can handle.
This becomes acute in 2026 because of three developments converging right now: rapid pricing-model changes by the major model providers, short-notice model deprecations (a model is retired before you can migrate), and the search by many SMEs for EU alternatives on sovereignty grounds. That this is no bogeyman is shown by a real example: OpenAI deprecated gpt-4.5-preview on 14 April 2025 and turned the model off in the API three months later, on 14 July 2025 (VentureBeat) — anyone who had built firmly on it had to migrate within that window.
The five AI vendor lock-in risks — and how to counter them
To avoid lock-in, you have to know the concrete scenarios. Each risk has both levers: the technical and the contractual countermeasure.
| Risk | Impact | Countermeasure (technical + contractual) |
|---|---|---|
| Price explosion | Running costs double, the budget tips over | Multi-model routing via an abstraction layer; contractual price-change/termination clause |
| Model shutdown | Workflow breaks because the model is deprecated | Model-agnostic integration + tested fallback; contractual notice/transition periods |
| Provider insolvency | The service disappears, data possibly unreachable | Self-hosted/open-source fallback; data-return and escrow clause |
| Regulatory stop | The provider may no longer offer the service in the EU | EU-capable fallback option evaluated in advance; data-residency and compliance clause |
| Data breach | Breach of trust, obligation to switch immediately | Portability in open formats; data processing agreement with deletion and return obligations |
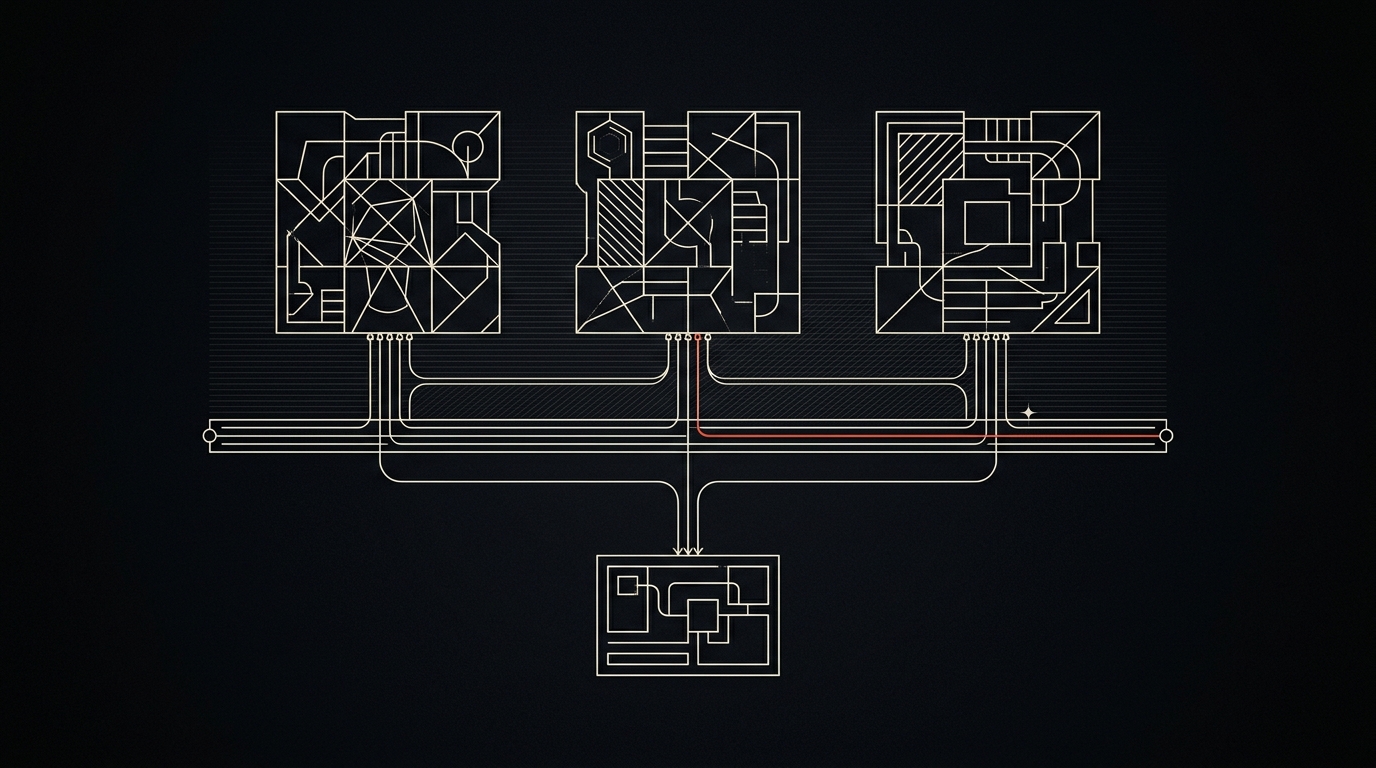
The abstraction layer separates your business logic from the specific model: providers become interchangeable, and switching shifts from a code rebuild to a configuration change — with the real residual effort of re-evaluating semantic model differences (tool calling, JSON mode, prompt behavior).
Multi-model architecture: technical independence
The most effective technical insurance against lock-in is not to bind yourself tightly to one model in the first place. A model-agnostic architecture separates your business logic from the specific AI interface.
Decouple business logic from the model
Your workflows, decision rules, and data flows should not know which model is answering — only that an answer is coming. Concretely: your application code knows only an internal interface (input → structured response); behind it, a thin adapter layer encapsulates the provider-specific request format, the parsing of the response, and the mapping onto your internal schema. Model name, provider, and parameters come from configuration, not from code. That way, switching models stays a change in one place — the call doesn’t change, only the adapter and the configuration behind it.
Abstraction layer / model gateway
A model gateway is a unified interface in front of multiple providers. Instead of writing separate code for each provider, you talk to one API — and the gateway translates to the respective provider protocol and routes the request. Tools such as LiteLLM (open source, self-hostable) or OpenRouter (hosted) serve here as generic examples; LiteLLM, for instance, supports more than 100 models behind a single, OpenAI-compatible API and can be self-operated, so that your data and your proxy stay with you (techjacksolutions.com, OpenRouter Blog). The point is not the tool, but the principle: switching providers without rebuilding code.
To be honest, the gateway has a cost side too: it is an additional hop (latency per request), and the proxy itself becomes a potential single point of failure — if it goes down, every provider behind it goes down with it. You relocate complexity rather than eliminate it: auth and key management, rate limits/quota per provider, retry and timeout logic, and observability (logging, tracing, cost attribution) now live at the gateway. This layer has to be designed redundantly and monitored, otherwise you trade vendor lock-in for gateway risk. A self-hosted gateway gives you data sovereignty but costs operations; a hosted one takes operations off your hands but creates a new dependency.
Multi-model routing
With a gateway, you can pick the right model for each task: a cheap, fast model for simple classification, a flagship model for complex reasoning. This not only lowers costs, it also spreads the risk across multiple providers. Specific savings figures are widely circulated — treat them as vendor claims, not guarantees, and measure for your own use case.
Where routing breaks in practice is something you should know before you build on it: providers differ in tool-calling and JSON-mode semantics (schema strictness, parallel calls, error behavior on invalid output), in tokenizer and context window (same prompt, different token count and different cost), and in prompt behavior itself — a prompt that runs reliably on model A can drift on model B. These very semantic differences are the actual migration effort that the abstraction layer does not abstract away: it unifies the call, not the behavior. In practice that means each target/fallback provider needs its own prompt set and has to pass through the same eval suite before you switch over in production — otherwise a silent quality drop (eval drift) masquerades as a “successful” switch.
Self-hosted fallback
For the worst case — provider gone, price untenable, compliance stop — an open-source LLM as an emergency fallback is worthwhile (for example, via Ollama locally or in an EU cloud). To be honest: open-source models don’t always reach the quality of the flagships, and operation and hardware take effort. But as a resilience anchor — not necessarily as a permanent solution — the fallback pays for itself. More on this in our consulting on on-premise LLMs, costs, and hardware.
Use open standards
Wherever possible, rely on open API formats and interoperability standards (such as the Model Context Protocol). The more standardized your interfaces, the weaker the lock-in. As of 2026, these standards are still in flux — assess them realistically, don’t sell them as a finished solution.
For the bigger picture, read our article on EU-hosted vs. US LLMs and data sovereignty.
Data portability: your data belongs to you — if the contract secures it
A model-agnostic architecture is of little use if your data is effectively trapped with the provider. Two questions decide the matter:
Can you get your data exported — in open formats? Demand export in JSON/CSV/PDF, complete audit logs, and — often forgotten — your vector embeddings. Embeddings without the model have limited value, but for a migration they are often worth their weight in gold.
Who owns the fine-tuning data and derived artifacts when you switch? This is the biggest blind spot in most guides. If you have fine-tuned a model with your data, the legal question is: who holds the usage rights to the result? Do you get the training data and the adapted artifact back, or deleted? This is an IP and usage-rights question — and it belongs in the contract before you fine-tune.
Contract clauses against lock-in
Now to the contractual lever — it decides whether you get a clean exit. (Note: general legal information, not legal advice for an individual case.)
Exit/migration clause. The centerpiece. It should include: specific export formats, deadlines for providing data, an obligation to provide migration support, governed data deletion/retention after the end of the contract, and transparency on costs.
Data-portability and return clause. Ensures that you receive data during and after the contract in a usable form — including derived artifacts.
Data processing agreement (Auftragsverarbeitungsvertrag, AVV) under Art. 28 GDPR. When personal data is involved, no AI service without a data processing agreement. Govern sub-processors and data residency. Note the conflict between US access rights (CLOUD Act) and Art. 48 GDPR — wherever possible, contractually stipulate processing within the EU.
Usage rights/IP, SLA, termination, price adjustment. Clear usage rights to outputs and fine-tunes, robust service levels, fair notice periods, and a price-change clause with a special right of termination in the event of material increases.
EU Data Act: which switching rights you already have by law
Much of what you used to have to negotiate hard for has been mandated by law since 2025. The EU Data Act (Regulation (EU) 2023/2854) has applied EU-wide since 12 September 2025 (anwaltskanzlei-schutt.de, Deloitte Legal). For cloud and data-processing services — which many AI services count as — it confers concrete switching rights:
| Obligation / right | Content | Effective date |
|---|---|---|
| Contractual anchoring | The switching right must be expressly stated in the contract (Art. 25) | since 12 Sep 2025 |
| Notice period | max. 2 months from the declaration of intent to switch | since 12 Sep 2025 |
| Transition period | 30-day transition/porting period (Art. 25; if technically infeasible → up to max. 7 months) | since 12 Sep 2025 |
| Switching charges | permitted only on a cost-recovery basis | until 11 Jan 2027 |
| Ban on switching charges | complete ban (Art. 29(2)) | from 12 Jan 2027 |
| Open interfaces | obligation to interoperability/open standards | since 12 Sep 2025 |
Sources: Deloitte Legal — Cloud Switching under the EU Data Act, IT-Recht-Kanzlei.
An important distinction: the Data Act governs provider switching, the GDPR governs the protection of personal data, and the EU AI Act governs the requirements for AI systems themselves — three different bodies of law with points of contact. Special questions can arise for specific AI constellations; don’t rely blindly on a blanket application. More on the regulatory framework in our overview of the EU AI Act for businesses.
Exit strategy in practice: plan, test, documentation
Rights and architecture are useless if nobody has rehearsed the exit. Three building blocks turn theory into resilience:
- Exit plan as a governance document. Who switches to where, with which data, in what order, in what time frame? In writing, kept current.
- Annual exit test. Once a year, migrate a non-critical workload to the fallback as a test. What is never rehearsed rarely works when it counts.
- Documentation for audit and oversight. Record that the plan and the test exist — as evidence of due diligence in practice.
Conclusion
You don’t solve AI vendor lock-in with technology or law, but with both: a model-agnostic architecture that makes switching technically trivial, and contracts that secure your data, rights, and deadlines for you — flanked by the switching rights the EU Data Act already grants you. It is precisely this seam between code and clause where most projects fail.
If you want to know how dependent your AI stack really is today — and how to secure it technically and contractually in one move: arrange an initial consultation. Architecture review and contract review from a single source, from a business lawyer who also develops.
FAQ
What does AI vendor lock-in mean?
AI vendor lock-in is the dependence on a single provider that makes switching technically, contractually, or data-wise difficult. It arises through code hard-wired to proprietary APIs, unfavorable contracts, or data and fine-tunes that are usable only with the provider.
How do I avoid dependence on a single AI provider?
On three levels: technically, through a model-agnostic architecture with an abstraction layer and a fallback; contractually, through exit, portability, and data processing agreement clauses; and data-wise, through export in open formats. The switching rights of the EU Data Act provide additional support.
Do I need several LLM providers in parallel?
Not necessarily in production simultaneously, but your architecture should keep a second provider activatable at any time. A fallback connected via an abstraction layer and tested regularly is often enough — it lowers the risk without doubling your operations.
Which contract clauses protect against AI vendor lock-in?
Above all, an exit/migration clause (export formats, deadlines, migration support, deletion, costs), a data-portability clause, a data processing agreement under Art. 28 GDPR with a data-residency provision, plus clear usage rights and a price-change clause with a special right of termination.
When are switching charges for cloud services banned?
Under the EU Data Act, switching charges are completely banned from 12 January 2027; until then, providers may charge only cost-recovery fees. The remaining switching rights (max. 2 months’ notice, 30 days’ transition — extendable to up to 7 months in individual cases) have already applied since 12 September 2025 (Deloitte Legal).
Note: This article offers general legal and technical information. This is general information, not legal advice. As of: February 2026 — verify the legal situation and deadlines before making decisions.
Sources — as of 23.02.2026
- Deloitte Legal — Cloud Switching nach dem EU Data Act
- IT-Recht-Kanzlei — EU Data Act: Update für Hosting-/SaaS-AGB
- Anwaltskanzlei Schutt — EU Data Act: Geltung ab 12.09.2025
- Deloitte Legal — EU Data Act: Maßnahmenplanung & Chancen
- OpenRouter Blog — LLM Gateway: What It Is and How to Choose One
- TechJack Solutions — OpenRouter vs LiteLLM (2026)
- Merge.dev — LLM routing: overview, strategies, and tools
- VentureBeat — OpenAI moves forward with GPT-4.5 deprecation in API

Leon Lotz
Leon Lotz is a business lawyer and founder of MusketierSoftware. He combines legal depth with real software craft.

