AI & Law
Understanding Context Windows & Token Limits: What 1 Million Tokens Really Mean
“1 million tokens” now sits on every other AI spec sheet — and is almost always misread. The number sounds like limitless memory. In practice it governs three very concrete things: how much a model actually understands in one shot, what a request costs, and which data you send out of the house in the process. Confuse them, and you’ll plan budgets wrong, overestimate output quality, and underestimate the compliance risk.
This article clears that up — from a dual perspective: technically sound (what tokens, context windows, and the quadratic attention cost mechanics really are) and legally grounded (what large contexts mean for the GDPR and for governance). With conversion and cost tables you can use directly for your own calculations.
As of February 2026 — model sizes and prices change quickly. Verify specific figures against the official provider documentation before making decisions.
What is a token?
A token is the smallest processing unit of a language model: a whole word, part of a word, a single character, or a punctuation mark. Models don’t “read” letters or words — they read these tokens. Every input and every response is broken down into tokens — and billed by the token.
As a rough rule of thumb for English text: 1 token ≈ 4 characters ≈ ¾ of a word, so roughly 1,000 tokens ≈ 750 words. This rule is handy, but it’s only an estimate.
For German text, the overhead is noticeably higher. Compound words (“Krankenversicherungsunternehmen”), umlauts, and productive word formation mean that, depending on the source, German requires roughly 20–30% more tokens than words — empirically about 1.2 to 1.3 tokens per word (jina.ai). It’s a detail many tech blogs overlook, but one that feeds straight into costs for German-speaking companies.
Important: Rules of thumb remain estimates. Only the tokenizer of the specific model delivers the exact token count. Anthropic, for example, recommends the model’s own
count_tokensendpoint for precise figures; third-party estimators (e.g., tiktoken) are significantly off for Claude tokens. Anyone planning budgets should cross-check with the actual tokenizer.
What is a context window?
The context window is the upper limit of what the model can process at the same time. Three things share this window:
- the input (prompt, inserted documents, instructions),
- the conversation history so far, and
- the model’s response.
If the window is small, the AI “forgets” earlier content in long conversations or can’t take in long documents in one piece. If it’s large, entire bodies of contracts, code repositories, or knowledge bases can be analyzed in a single pass — at least in theory. The section on “Lost in the Middle” explains why “in theory.”
Converting tokens into words & pages
The following table makes the orders of magnitude tangible (rule of thumb for English text; one A4 page ≈ 500 words of running text):
| Tokens | ≈ Words (rule of thumb) | ≈ A4 pages |
|---|---|---|
| 1,000 | ~750 | ~1.5 |
| 10,000 | ~7,500 | ~15 |
| 100,000 | ~75,000 | ~150 |
| 1,000,000 | ~750,000 | ~1,500 |
Do the math for German text: Because of the higher token density, the same text consumes more tokens — more per word. At 1.2–1.3 tokens per word, 1 million tokens correspond to roughly 770,000–830,000 words of German running text. More important than the exact word count: the same request costs 20–30% more tokens — and therefore more money — on German than the English rule of thumb suggests. When in doubt, measure with the model’s tokenizer.
What 1 million tokens really mean
A million tokens sounds abstract. In concrete terms it corresponds to roughly 1,500 A4 pages — that is, about:
- a complete contract binder including attachments, or a smaller M&A data room,
- several average non-fiction books,
- a mid-sized code repository,
- a stack of annual financial statements and tax documents.
For mid-sized businesses, this means: instead of feeding in one document after another, you can analyze an entire matter in one piece — contract review across the whole bundle, a code review of a project, the evaluation of a knowledge base.
Reality check: The advertised maximum size is not the same as the reliably usable size. A model that takes in 1 million tokens does not automatically use every piece of information within it equally well. The next relevant section shows why.
How large is the context window of common models?
Rather than freezing individual specs, it helps to group them into tiers — supplemented by a few dated, verified anchors (as of February 2026):
| Tier | Order of magnitude | Typical use |
|---|---|---|
| Small | 8K – 32K tokens | short chats, single emails, small snippets |
| Medium | 128K – 200K | longer documents, multi-step conversations |
| Large | 1 million+ | whole bundles of files, repos, knowledge bases |
Verified anchors (as of February 2026, checked against provider/market sources):
- Anthropic Claude (Opus 4.6/4.7/4.8, Sonnet 4.6): 1 million token context window, generally available at standard pricing with no long-context surcharge (Anthropic docs: Pricing · Models overview).
- OpenAI and Google Gemini: as of the current state, these also sit in the range of several hundred thousand to over one million tokens, depending on the model variant. Exact values fluctuate between versions and are often reported inconsistently in third-party sources — only each provider’s current documentation is authoritative (OpenAI Platform, Google AI for Developers).
Mandatory disclaimer: Models and figures change frequently and are often reported inconsistently in secondary blogs. Check against the official provider documentation before any decision. The numbers above are dated as orientation, not a standing guarantee.
What does a large context window cost?
AI APIs bill per token — and they distinguish input (everything that goes in) from output (everything that comes out). Output is usually significantly more expensive. For orientation (Anthropic, as of February 2026, per 1 million input/output tokens): Haiku 4.5 ~$1/$5, Sonnet 4.6 ~$3/$15, Opus 4.8 ~$5/$25 (Anthropic pricing).
Quadratic ≠ final price — the most important mistake in reasoning: You’ll often read “double the context window = quadruple the cost.” That holds for the theoretical compute cost of naive self-attention, which mathematically grows quadratically with sequence length — not for the API end-customer price. In practice, techniques like KV caching and FlashAttention dampen this cost considerably, and during actual generation it grows roughly linearly per token; what is quadratic is mainly the one-time processing of the prompt (prefill). The API price is decoupled from all this and usually linear per token. Some providers levy a long-context surcharge above certain thresholds (around ~200K tokens, say), others don’t (Anthropic, for instance, doesn’t). Keep the two cleanly apart, or your calculations will be wrong.
Worked example (methodology, not a frozen price statement): Suppose a team makes 100 requests a day, each with 50,000 tokens of input and 2,000 tokens of output, to a model priced at $3/$15 per 1 million tokens:
- Input: 100 × 50,000 = 5 million tokens → 5 × $3 = $15/day
- Output: 100 × 2,000 = 200,000 tokens → 0.2 × $15 = $3/day
- Total: ~$18/day, so roughly $540/month — before any optimizations kick in.
Cutting costs (white-hat, documented):
- Load only what’s relevant — don’t reflexively dump the whole folder into the context.
- Prompt caching for recurring context segments: with Anthropic, the cached portion costs only about a tenth of the normal input price (so up to ~90% savings on it) (Anthropic docs: Prompt Caching).
- Batch API for non-time-critical bulk tasks: ~50% discount with Anthropic (Anthropic docs: Batch Processing).
- Context compression / compaction: summarize the history rather than carrying it along in full.
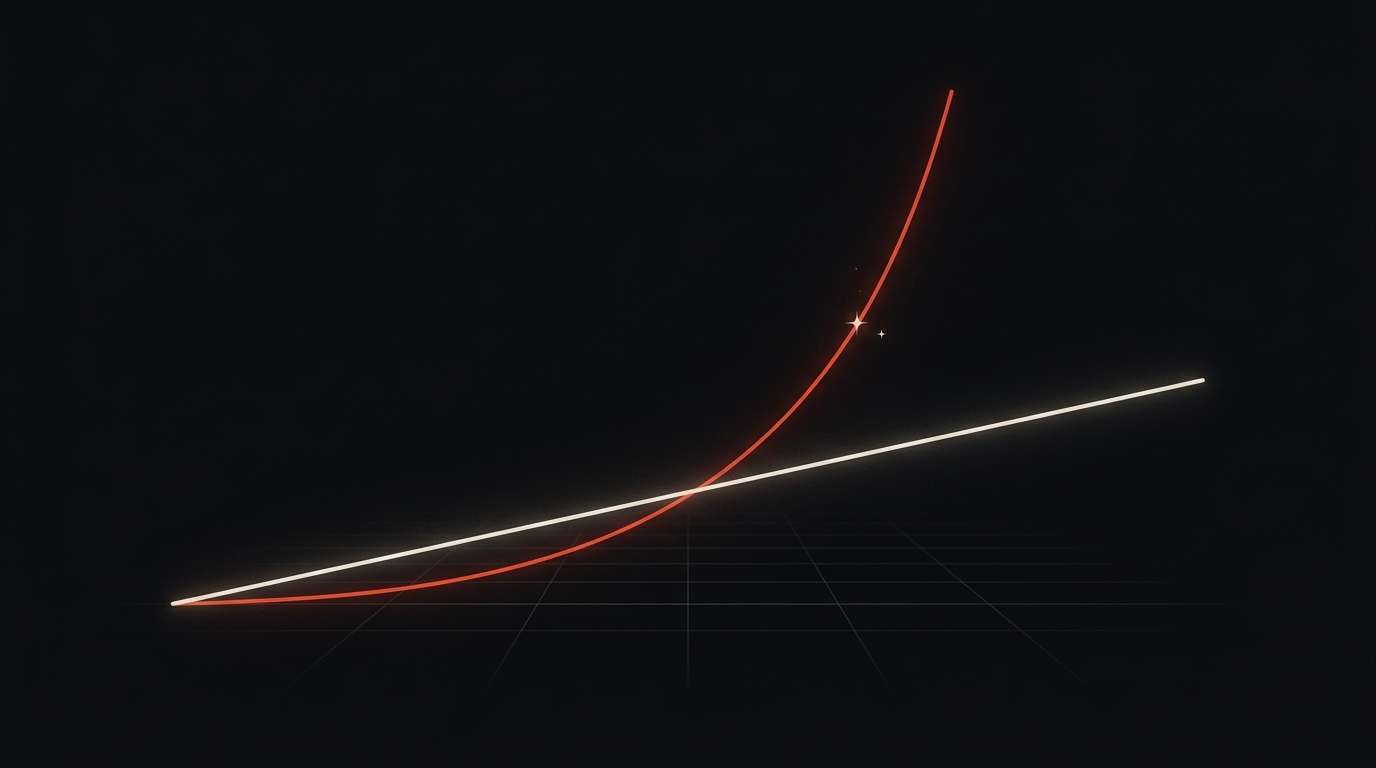
Two curves that are often confused: what you pay at the API (linear per token) is not the internal compute cost of self-attention (quadratic). That confusion is the source of the costliest planning mistake.
Why the AI “forgets” the middle (Lost in the Middle)
Even a huge window doesn’t use its contents evenly. The widely cited study “Lost in the Middle” (Liu et al., Stanford/UC Berkeley/Samaya AI, published in TACL) showed a U-shaped effect: models use information at the beginning and the end of the context far more reliably than information in the middle (MIT Press / TACL). This resembles the serial position effect from human memory research (primacy and recency bias).
The practical consequence: advertised context size ≠ effectively used context size. If you feed in 1,500 pages, you should place the most important material up front and at the end, structure it deliberately, and run critical analyses iteratively rather than in one mega-prompt.
What happens when the context window is full?
It helps to separate two layers here: the raw LLM API does not truncate by itself — it rejects the request or signals that the limit was exceeded (with Anthropic, for instance, via its own stop_reason). The truncation (the oldest context drops out) or summarization is behavior of the application layer or chat interface above it, not of the model. Sensible ways out:
- Context compression/compaction — summarize the history.
- RAG (Retrieval-Augmented Generation) — pull in only the relevant excerpts from a knowledge base as needed, instead of permanently keeping everything in the window.
Large context window or RAG?
Both have their place:
- A large context pays off for the one-off deep analysis of a clearly bounded set of documents — for instance, a complete due-diligence review.
- RAG wins for large, changing knowledge bases and when cost control matters: it loads only what’s needed and avoids dragging the full (expensive) context along on every request.
The underlying trade-off — load knowledge into the context, retrieve it via RAG, or train it into the model — is explored in RAG vs. fine-tuning for businesses. To approach the actual prompt construction systematically, From prompt engineering to context engineering covers the next step.
Data protection & cost as a leadership issue
This is where the topic becomes a matter for the C-suite. Anyone loading entire bundles of files into an AI sends a lot of data — often personal or confidential — out of the house. That touches on core obligations:
- Properly govern data processing on behalf of a controller (Auftragsverarbeitung, Art. 28 GDPR) — no AI tool without a data processing agreement.
- Check data residency: Is data transferred to a third country? Are there EU-based servers?
- Personal data and purpose limitation: the larger the context, the more likely data ends up in the request that has no business being there.
And: uncontrolled token consumption is not just a budget issue but a governance issue. Large contexts without a cost cap can throw both the IT bill and compliance off balance. There is also the regulatory frame: the obligations for general-purpose AI (GPAI) models under the EU AI Act have applied since 2 August 2025 — transparency and documentation requirements that must also be priced into your own AI governance (European Commission: AI Act).
This is general information, not legal advice.
Anyone who wants to use large contexts in a way that is both legally sound and cost-efficient needs both: the technical implementation and the legal assessment. This dual qualification — a business lawyer (Wirtschaftsjurist, a German degree combining law and business) who also builds the solution — is exactly what MusketierSoftware brings to AI consulting, from privacy-compliant tool selection to data-sovereign AI on EU/in-house servers. Behind the concept stands a business lawyer who develops the solution himself.
FAQ
How many tokens does a German text have?
As a rule of thumb, roughly 1.2–1.3 tokens per word — that is, 20–30% more tokens than the common English rule of thumb (1 token ≈ ¾ word) would suggest. Compound words and umlauts break down into more subword tokens in the tokenizer. Only the model’s tokenizer counts exactly.
Input or output tokens — which counts how?
Both count toward the context window and both are billed. Output is generally more expensive per token than input. So calculate them separately when planning costs.
What do you do when the context window is exceeded?
The raw API rejects the request; the truncation or summarization is handled by most chat interfaces on top of it. Solutions: compress the history (compaction), load only what’s relevant into the context, or pull in specific excerpts via RAG instead of keeping everything in the window.
Does a window twice as large mean four times the cost?
No — that mistake conflates compute cost with price. The API end price is usually linear per token. Only the internal attention compute cost grows quadratically. Some providers levy a long-context surcharge above certain thresholds; many don’t.
Is 1 million tokens enough for my documents?
By sheer volume, 1 million tokens corresponds to roughly 1,500 pages — usually enough for a contract binder or a repo. But: because of “Lost in the Middle,” not every piece of information is used equally reliably. For critical analyses, structure the input and proceed iteratively.
Conclusion
Context windows and tokens are not a marketing number but a planning metric: they determine how much the AI understands at once, what it costs, and where the limits lie. 1 million tokens is impressive — but only with an understanding of German token density, cost mechanics, “Lost in the Middle,” and data protection does it become a dependable plan.
Sources — as of 13.02.2026
- Anthropic models, context window & pricing (1M tokens, no long-context surcharge): Anthropic docs — Pricing · Models overview
- Prompt caching & batch savings: Anthropic docs — Prompt Caching · Batch Processing
- Context windows of other models change frequently — check the provider’s own documentation (OpenAI Platform, Google AI for Developers)
- EU AI Act, GPAI obligations applicable since 2 August 2025: European Commission — AI Act
- “Lost in the Middle” (Liu et al., TACL): MIT Press
- German token density (~1.2–1.3 tokens/word): jina.ai
- Definition of context window: ComputerWeekly
Note: Model sizes and prices age quickly. Verify the figures cited here against the official provider documentation (Anthropic/OpenAI/Google) before making decisions.

Leon Lotz
Leon Lotz is a business lawyer and founder of MusketierSoftware. He combines legal depth with real software craft.

