KI & Recht
Kontextfenster & Token-Limits verstehen: Was 1 Million Token wirklich bedeuten
„1 Million Token” steht heute auf jedem zweiten KI-Datenblatt — und wird fast immer falsch verstanden. Die Zahl klingt nach grenzenlosem Gedächtnis. In der Praxis entscheidet sie über drei sehr konkrete Dinge: wie viel ein Modell wirklich auf einen Schlag versteht, was eine Anfrage kostet, und welche Daten Sie dabei aus dem Haus geben. Wer das verwechselt, plant Budgets falsch, überschätzt die Ergebnisqualität und unterschätzt das Compliance-Risiko.
Dieser Artikel räumt damit auf — aus doppelter Perspektive: technisch sauber (was Token, Kontextfenster und die quadratische Attention-Kostenmechanik wirklich sind) und juristisch eingeordnet (was große Kontexte für DSGVO und Governance bedeuten). Mit Umrechnungs- und Kostentabellen, die Sie direkt für die eigene Kalkulation verwenden können.
Stand: Februar 2026 — Modellgrößen und Preise ändern sich schnell. Konkrete Zahlen vor Entscheidungen gegen die offizielle Anbieter-Doku prüfen.
Was ist ein Token?
Ein Token ist die kleinste Verarbeitungseinheit eines Sprachmodells: ein ganzes Wort, ein Wortteil, ein einzelnes Zeichen oder ein Satzzeichen. Modelle „lesen” keine Buchstaben und keine Wörter, sondern diese Token. Jede Eingabe und jede Antwort wird in Token zerlegt — und nach Token abgerechnet.
Als grobe Faustregel für englischen Text gilt: 1 Token ≈ 4 Zeichen ≈ ¾ Wort, also rund 1.000 Token ≈ 750 Wörter. Diese Regel ist praktisch, aber nur eine Schätzung.
Für deutschen Text liegt der Aufwand spürbar höher. Komposita („Krankenversicherungsunternehmen”), Umlaute und die produktive Wortbildung führen dazu, dass Deutsch je nach Quelle rund 20–30 % mehr Token als Wörter benötigt — empirisch etwa 1,2 bis 1,3 Token pro Wort (jina.ai). Das ist ein Detail, das viele Tech-Blogs übersehen, das für deutschsprachige Unternehmen aber direkt auf die Kosten durchschlägt.
Wichtig: Faustregeln bleiben Schätzungen. Die exakte Token-Zahl liefert nur der Tokenizer des jeweiligen Modells. Anthropic etwa empfiehlt für genaue Werte den modelleigenen
count_tokens-Endpoint; fremde Schätzer (z. B. tiktoken) liegen bei Claude-Token deutlich daneben. Wer Budgets plant, sollte mit dem echten Tokenizer gegenrechnen.
Was ist ein Kontextfenster?
Das Kontextfenster ist die Obergrenze dessen, was das Modell gleichzeitig verarbeiten kann. In dieses Fenster teilen sich drei Dinge:
- die Eingabe (Prompt, eingefügte Dokumente, Anweisungen),
- der bisherige Gesprächsverlauf und
- die Antwort des Modells.
Ist das Fenster klein, „vergisst” die KI in langen Gesprächen frühere Inhalte oder kann lange Dokumente nicht am Stück erfassen. Ist es groß, lassen sich ganze Vertragswerke, Code-Repositories oder Wissensdatenbanken in einem Durchgang analysieren — zumindest in der Theorie. Warum „in der Theorie”, klärt der Abschnitt zu „Lost in the Middle”.
Token in Wörter & Seiten umrechnen
Die folgende Tabelle macht Größenordnungen greifbar (Faustregel für englischen Text; eine DIN-A4-Seite ≈ 500 Wörter Fließtext):
| Token | ≈ Wörter (Faustregel) | ≈ DIN-A4-Seiten |
|---|---|---|
| 1.000 | ~750 | ~1,5 |
| 10.000 | ~7.500 | ~15 |
| 100.000 | ~75.000 | ~150 |
| 1.000.000 | ~750.000 | ~1.500 |
Für deutsche Texte nachrechnen: Wegen der höheren Token-Dichte verbraucht derselbe Text mehr Token — pro Wort fällt also mehr an. Bei 1,2–1,3 Token pro Wort entsprechen 1 Million Token für deutschen Fließtext rund 770.000–830.000 Wörter. Wichtiger als die genaue Wortzahl: Dieselbe Anfrage kostet auf Deutsch 20–30 % mehr Token — und damit mehr Geld — als die englische Faustregel vermuten lässt. Im Zweifel mit dem Modell-Tokenizer messen.
Was 1 Million Token wirklich bedeuten
Eine Million Token klingt abstrakt. Konkret entspricht das rund 1.500 DIN-A4-Seiten — also etwa:
- ein kompletter Vertragsordner samt Anlagen oder ein kleinerer M&A-Datenraum,
- mehrere durchschnittliche Sachbücher,
- ein mittelgroßes Code-Repository,
- ein Stapel Jahresabschlüsse und Steuerunterlagen.
Für den Mittelstand heißt das: Statt ein Dokument nach dem anderen zu füttern, lässt sich ein ganzer Sachverhalt am Stück analysieren — Vertragsprüfung über das gesamte Konvolut, Code-Review eines Projekts, Auswertung einer Wissensbasis.
Reality-Check: Die beworbene Maximalgröße ist nicht gleich der zuverlässig nutzbaren Größe. Ein Modell, das 1 Mio. Token aufnimmt, nutzt nicht automatisch jede Information darin gleich gut. Warum, zeigt der nächste relevante Abschnitt.
Wie groß ist das Kontextfenster gängiger Modelle?
Statt einzelne Specs einzufrieren, hilft eine Einteilung in Tiers — ergänzt um wenige datierte, verifizierte Anker (Stand Februar 2026):
| Tier | Größenordnung | Typischer Einsatz |
|---|---|---|
| Klein | 8K – 32K Token | kurze Chats, einzelne E-Mails, kleine Snippets |
| Mittel | 128K – 200K | längere Dokumente, mehrstufige Gespräche |
| Groß | 1 Mio.+ | ganze Aktenkonvolute, Repos, Wissensbasen |
Verifizierte Anker (Stand Februar 2026, gegen Anbieter-/Marktquellen geprüft):
- Anthropic Claude (Opus 4.6/4.7/4.8, Sonnet 4.6): 1 Mio. Token Kontextfenster, allgemein verfügbar zu Standardpreisen ohne Long-Context-Aufschlag (Anthropic-Doku: Preise · Modellübersicht).
- OpenAI und Google Gemini: bewegen sich nach derzeitigem Stand ebenfalls im Bereich mehrerer hunderttausend bis über eine Million Token, je nach Modellvariante. Die genauen Werte schwanken zwischen Versionen und sind in Drittquellen oft uneinheitlich — verbindlich ist allein die jeweils aktuelle Anbieter-Doku (OpenAI Platform, Google AI for Developers).
Pflicht-Disclaimer: Modelle und Werte ändern sich häufig und werden in Sekundär-Blogs oft widersprüchlich angegeben. Vor jeder Entscheidung gegen die offizielle Anbieter-Doku prüfen. Die obigen Zahlen sind als Orientierung datiert, nicht als Dauer-Zusage.
Was kostet ein großes Kontextfenster?
KI-APIs rechnen pro Token ab — und trennen dabei Input (alles, was hineingeht) von Output (alles, was herauskommt). Output ist meist deutlich teurer. Zur Einordnung (Anthropic, Stand Februar 2026, je 1 Mio. Token Input/Output): Haiku 4.5 ~1 $/5 $, Sonnet 4.6 ~3 $/15 $, Opus 4.8 ~5 $/25 $ (Anthropic-Preisübersicht).
Quadratisch ≠ Endpreis — der wichtigste Denkfehler: Man liest oft „doppeltes Kontextfenster = vierfache Kosten”. Das gilt für den theoretischen Rechenaufwand der naiven Self-Attention, die rechnerisch quadratisch mit der Sequenzlänge wächst — nicht für den API-Endkundenpreis. In der Praxis dämpfen Verfahren wie KV-Caching und FlashAttention diesen Aufwand erheblich, und beim eigentlichen Generieren wächst er pro Token annähernd linear; quadratisch ist vor allem die einmalige Verarbeitung des Prompts (Prefill). Der API-Preis ist davon entkoppelt und in der Regel linear pro Token. Manche Anbieter erheben ab Schwellen (etwa ab ~200K Token) einen Long-Context-Aufschlag, andere nicht (Anthropic z. B. nicht). Beides sauber trennen, sonst kalkuliert man falsch.
Rechenbeispiel (Methodik, keine eingefrorene Preisaussage): Angenommen, ein Team stellt täglich 100 Anfragen mit je 50.000 Token Input und 2.000 Token Output an ein Modell mit 3 $/15 $ pro 1 Mio. Token:
- Input: 100 × 50.000 = 5 Mio. Token → 5 × 3 $ = 15 $/Tag
- Output: 100 × 2.000 = 200.000 Token → 0,2 × 15 $ = 3 $/Tag
- Summe: ~18 $/Tag, also grob 540 $/Monat — bevor Optimierungen greifen.
Kosten senken (white-hat, dokumentiert):
- Nur Relevantes laden — nicht reflexhaft den ganzen Ordner in den Kontext kippen.
- Prompt Caching für wiederkehrende Kontextteile: bei Anthropic kostet der zwischengespeicherte Anteil nur rund ein Zehntel des normalen Input-Preises (also bis ~90 % Ersparnis darauf) (Anthropic-Doku: Prompt Caching).
- Batch-API für nicht-zeitkritische Massenaufgaben: bei Anthropic ~50 % Rabatt (Anthropic-Doku: Batch Processing).
- Kontext-Komprimierung / Compaction: Verlauf zusammenfassen statt vollständig mitzuschleppen.
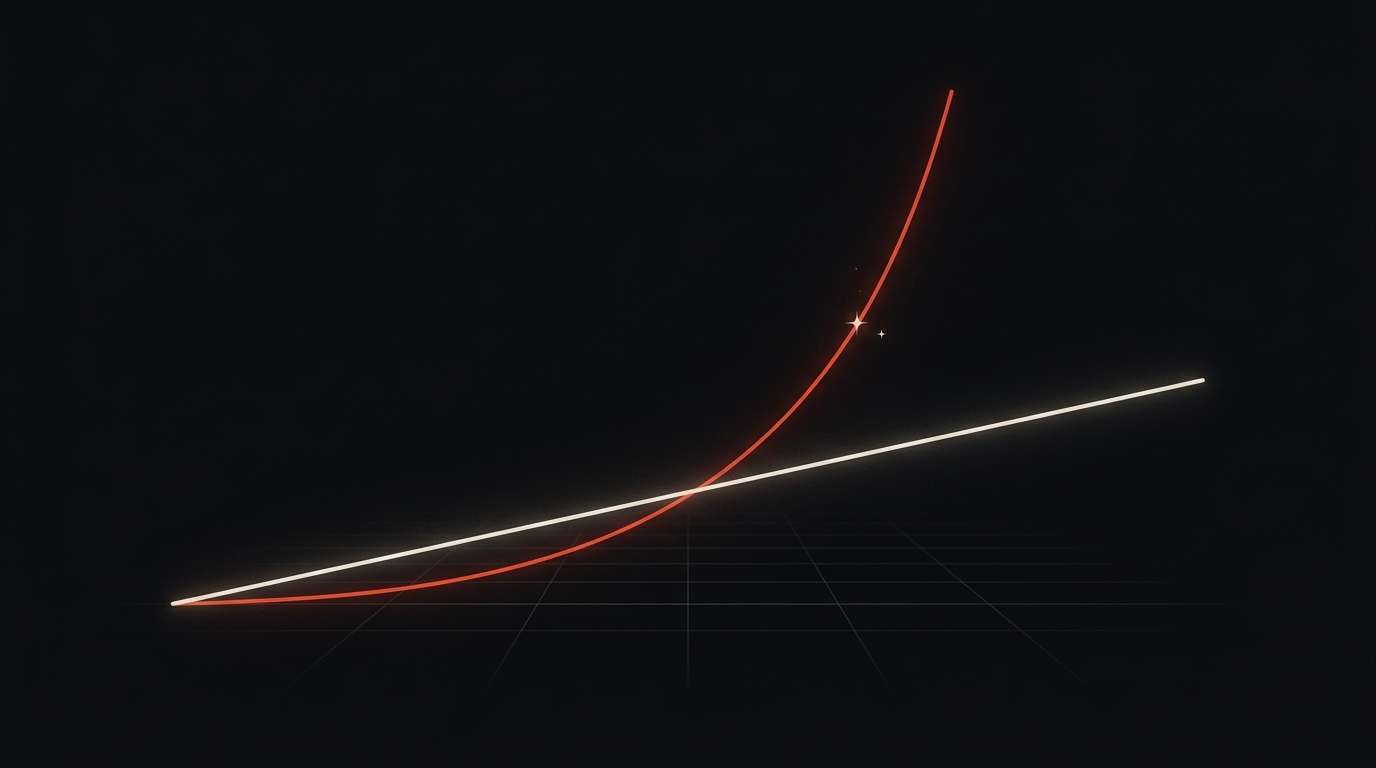
Zwei Kurven, die oft verwechselt werden: Was Sie an der API zahlen (linear pro Token), ist nicht der interne Rechenaufwand der Self-Attention (quadratisch). Aus dieser Verwechslung entsteht der teuerste Planungsfehler.
Warum die KI die Mitte „vergisst” (Lost in the Middle)
Auch ein riesiges Fenster nutzt seine Inhalte nicht gleichmäßig. Die viel zitierte Studie „Lost in the Middle” (Liu et al., Stanford/UC Berkeley/Samaya AI, veröffentlicht in den TACL) zeigte einen U-förmigen Effekt: Modelle verwerten Informationen am Anfang und am Ende des Kontexts deutlich zuverlässiger als die in der Mitte (MIT Press / TACL). Das ähnelt dem Serienpositionseffekt aus der menschlichen Gedächtnisforschung (Primacy- und Recency-Bias).
Die praktische Konsequenz: beworbene Kontextgröße ≠ effektiv genutzte Kontextgröße. Wer 1.500 Seiten hineingibt, sollte das Wichtigste nach vorn und nach hinten stellen, gezielt strukturieren und kritische Analysen iterativ statt in einem Mega-Prompt durchführen.
Was passiert bei vollem Kontextfenster?
Hier lohnt es, zwei Ebenen zu trennen: Die rohe LLM-API schneidet nicht selbst ab — sie lehnt die Anfrage ab bzw. signalisiert das Überschreiten (bei Anthropic etwa über einen eigenen stop_reason). Das Abschneiden (ältester Kontext fällt weg) oder Zusammenfassen ist Verhalten der darüberliegenden Anwendung bzw. der Chat-Oberfläche, nicht des Modells. Sinnvolle Auswege:
- Kontext-Komprimierung/Compaction — den Verlauf zusammenfassen.
- RAG (Retrieval-Augmented Generation) — nur die jeweils relevanten Ausschnitte aus einer Wissensbasis nachladen, statt alles dauerhaft im Fenster zu halten.
Großes Kontextfenster oder RAG?
Beides hat seinen Platz:
- Großer Kontext lohnt für die einmalige Tiefenanalyse eines klar abgegrenzten Dokumentensatzes — etwa eine vollständige Due-Diligence-Prüfung.
- RAG gewinnt bei großen, sich ändernden Wissensbasen und wenn Kostenkontrolle zählt: Es lädt nur das Nötige und vermeidet, dass jede Anfrage den vollen (teuren) Kontext mitschleppt.
Die grundsätzliche Abwägung — Wissen in den Kontext laden, per RAG abrufen oder ins Modell trainieren — vertieft der Beitrag RAG vs. Fine-Tuning für Unternehmen. Wer beim eigentlichen Prompt-Aufbau systematisch vorgehen will, findet im Beitrag Vom Prompt Engineering zum Context Engineering die nächste Stufe.
Datenschutz & Kosten als Führungsthema
Hier wird das Thema zur Chefsache. Wer ganze Aktenkonvolute in eine KI lädt, schickt viele — oft personenbezogene oder vertrauliche — Daten aus dem Haus. Das berührt zentrale Pflichten:
- Auftragsverarbeitung sauber regeln (Art. 28 DSGVO) — kein KI-Tool ohne AV-Vertrag.
- Datenresidenz prüfen: Werden Daten in ein Drittland übertragen? Gibt es EU-Server?
- Personenbezug und Zweckbindung: Je größer der Kontext, desto eher landen Daten in der Anfrage, die dort nicht hingehören.
Und: Unkontrollierter Token-Verbrauch ist nicht nur ein Budget-, sondern ein Governance-Thema. Große Kontexte ohne Kostendeckel können sowohl die IT-Rechnung als auch die Compliance ins Wanken bringen. Hinzu kommt der regulatorische Rahmen: Die Pflichten für KI-Modelle mit allgemeinem Verwendungszweck (GPAI) nach der EU-KI-Verordnung gelten seit dem 2. August 2025 — Transparenz- und Dokumentationsanforderungen, die auch in die eigene KI-Governance einzupreisen sind (EU-Kommission: KI-Gesetz).
Dieser Artikel ist allgemeine Information und keine Rechtsberatung im Einzelfall.
Wer große Kontexte rechtssicher und kosteneffizient einsetzen will, braucht beides: die technische Umsetzung und die juristische Bewertung. Genau diese Doppelqualifikation — Wirtschaftsjurist, der die Lösung auch baut — bringt MusketierSoftware in der KI-Beratung ein, von der datenschutzkonformen Tool-Auswahl bis zur datensouveränen KI auf EU-/eigenen Servern. Hinter dem Konzept steht ein Wirtschaftsjurist, der die Lösung selbst entwickelt.
FAQ
Wie viele Token hat ein deutscher Text?
Als Faustregel rund 1,2–1,3 Token pro Wort — also 20–30 % mehr Token, als die gängige englische Faustregel (1 Token ≈ ¾ Wort) vermuten lässt. Komposita und Umlaute zerfallen im Tokenizer in mehr Subword-Token. Exakt zählt nur der Modell-Tokenizer.
Input- oder Output-Token — was zählt wie?
Beide zählen ins Kontextfenster und werden beide abgerechnet. Output ist in der Regel teurer pro Token als Input. Bei der Kostenplanung deshalb getrennt rechnen.
Was tun, wenn das Kontextfenster überschritten ist?
Die rohe API lehnt die Anfrage ab; das Abschneiden oder Zusammenfassen übernehmen die meisten Chat-Oberflächen darüber. Lösungen: den Verlauf komprimieren (Compaction), nur Relevantes in den Kontext laden oder per RAG gezielt Ausschnitte nachladen statt alles im Fenster zu halten.
Bedeutet ein doppelt so großes Fenster vierfache Kosten?
Nein — der Denkfehler verwechselt Rechenaufwand und Preis. Der API-Endpreis ist meist linear pro Token. Nur der interne Attention-Rechenaufwand wächst quadratisch. Manche Anbieter erheben ab Schwellen einen Long-Context-Aufschlag, viele nicht.
Reicht 1 Million Token für meine Dokumente?
Rein vom Volumen entsprechen 1 Mio. Token grob 1.500 Seiten — meist genug für einen Vertragsordner oder ein Repo. Aber: Wegen „Lost in the Middle” wird nicht jede Information gleich zuverlässig genutzt. Bei kritischen Analysen strukturieren und iterativ vorgehen.
Fazit
Kontextfenster und Token sind keine Marketing-Zahl, sondern eine Planungsgröße: Sie bestimmen, wie viel die KI auf einmal versteht, was es kostet und wo die Grenzen liegen. 1 Million Token sind beeindruckend — aber erst mit dem Wissen um DE-Token-Dichte, Kostenmechanik, „Lost in the Middle” und Datenschutz wird daraus ein belastbarer Plan.
Quellen — Stand 13.02.2026
- Anthropic Modelle, Kontextfenster & Preise (1 Mio. Token, kein Long-Context-Aufschlag): Anthropic-Doku — Preise · Modellübersicht
- Prompt Caching & Batch-Ersparnis: Anthropic-Doku — Prompt Caching · Batch Processing
- Kontextgrößen anderer Modelle ändern sich häufig — gegen die jeweilige Anbieter-Doku prüfen (OpenAI Platform, Google AI for Developers)
- EU-KI-Verordnung, GPAI-Pflichten seit 2. August 2025: EU-Kommission — KI-Gesetz
- „Lost in the Middle” (Liu et al., TACL): MIT Press
- DE-Token-Dichte (~1,2–1,3 Token/Wort): jina.ai
- Definition Kontextfenster: ComputerWeekly
Hinweis: Modellgrößen und Preise veralten schnell. Prüfen Sie die genannten Zahlen vor Entscheidungen gegen die offizielle Anbieter-Doku (Anthropic/OpenAI/Google).

Leon Lotz
Leon Lotz ist Wirtschaftsjurist und Gründer von MusketierSoftware. Er verbindet juristische Tiefe mit echtem Software-Handwerk.

